The case for Federated Search Engines
The problem with ‘relevance’
Search Engines have been on a relentless mission to organize the world’s information. They have been categorizing and sorting human knowledge and classifying intent. They are getting better at understanding context and are presenting users with the most relevant information.
Relevancy is calculated based on several factors. Initially, it was just the number of occurrences of the searched term on the page. This quickly evolved to the number of back-links to a page, with the underlying assumption that the most relevant information is the one that is linked to the most. We have come a long way since then and there has been a sea-change in the way relevancy of each link against each term is computed.
In their mission to give the most relevant and contextual information possible, search engines aside from signals given by the resources, now also rely on signals given by the user themselves. They include explicit data-points such as their location to hidden data points such as the kind of web-sites a user has visited in the past.
Users often have very specific searches. They are looking for a business/person/phenomenon and the pool of relevant results is much smaller in these cases. In this case, relevancy works as designed. The user gets to see the most useful information from a huge swath of irrelevant information.
In some cases however, the pool of relevant results is much larger. In this case, the search engines have to make a value call on which links/resources to surface. The marginal calls are often made on the what is considered relevant for each user. This is a problem.
Firstly, the engine make these calls on parameters that are often not only known to the user but also to folks building the algorithm that powers these engines. Secondly, these calls start a positive feedback loop where the engines of use the signal of a user clicking on a link as data to decide what to show the user the next time they search for the same term.
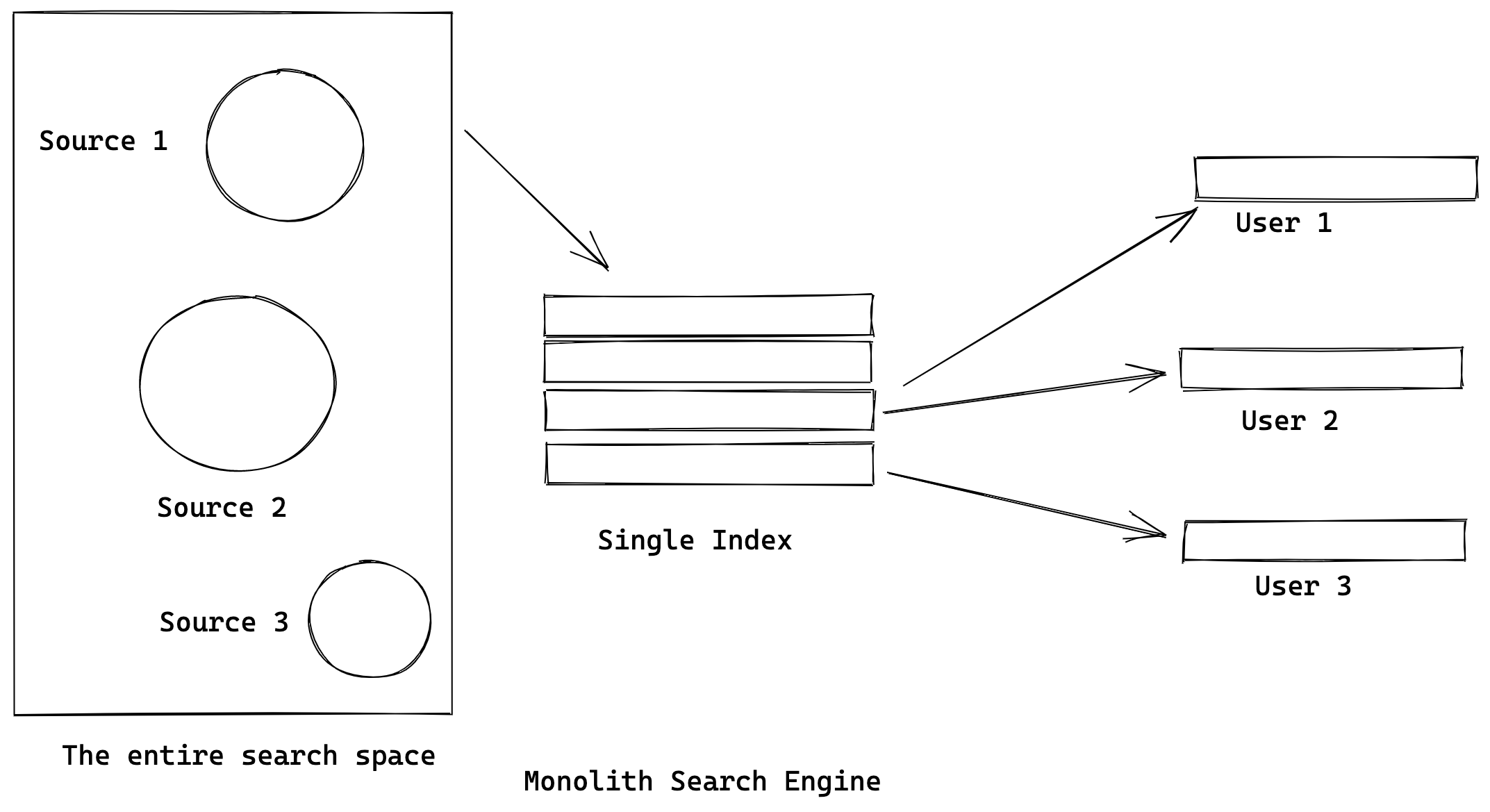
Monolith Search Engines scrape the entire web and use 1 index for their search. These indexes amass alot of information and the actual scraping is done indiscriminately. These indexes are really to good for specific searches.
Federated Search Engines
The user is abstracted from the notion of deciding what is relevant to them but the larger issue is that most users are un-aware that this abstraction exists. For most people in the industry, how the algorithm works is a known-unknown. However, for most people outside the tech-industry, the existence of such an algorithm is an unknown-unknown.
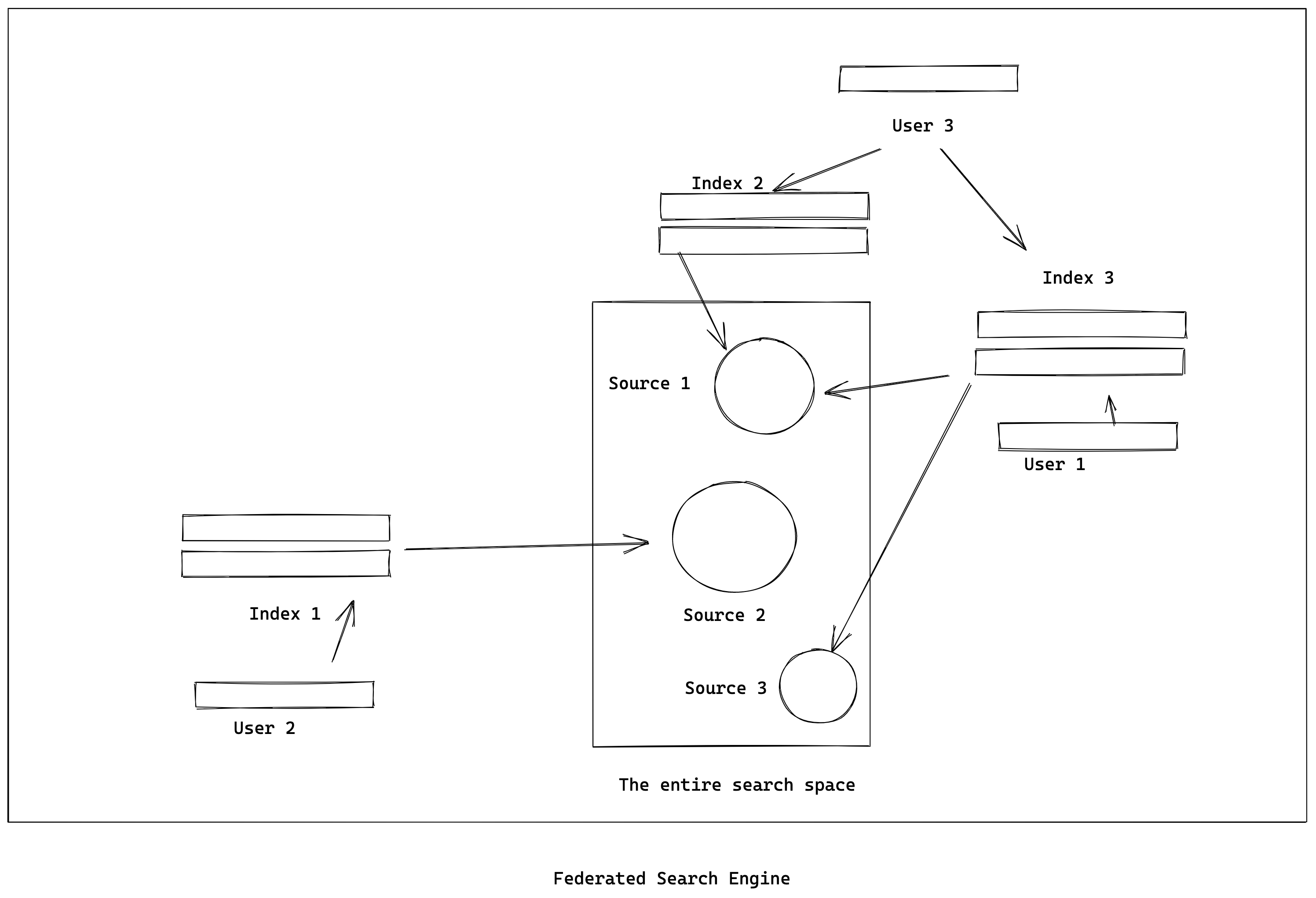
Federated Search Engines could in theory help with this issue.
Federated Search Engines could intentionally decide which sources to index and scrape. The intentionality could come with a world-view that the index would reflect. The scraping would not be done indiscriminately and the ‘bias’ would be explicit and made known.
Users with their own particular world views could decide which indexes to subscribe to and search against. This restores the idea of placing the onus of deciding relevancy back to the user.
Filter Bubbles v/s Walled Gardens
A seemingly obvious problem with Federated Search Engines is the reinforcement of bias or world-view by excluding websites with a counter world view. However, monolith search engines also suffer from the same problem. The only difference is that in the case of monolith search engines, the bias is implicit and it is not explicitly stated by the user.
Filter-bubbles only get created when the existence of the bubble is not known. By entrusting the users to choose to their indexes as per their world-view, the onus of holding and reinforcing the bias falls on the user. They may choose to balance their world-view by subscribing to different indexes but the choice would at least be explicit.
« Exploring SwiftUI
Why Amazon Wouldn't Survive in the Long Run »